AI Cost Management: Why Your Cloud Playbook Won’t Work for AI

Duan Van Der Westhuizen
SVP, Hybrid Cloud
Cloud bills shocked CFOs. AI bills confuse them.
This might sound like hyperbole, but it’s what we’re hearing from finance leaders. And it’s happening faster than most organizations anticipated.
In my last article, Cloud First to AI First: We’ve Seen This Movie Before, I argued that AI First is following the Cloud First playbook: the same arc from board curiosity to enterprise mandate, the same shadow IT risks, the same compliance learning curve. But there’s one area where the parallel breaks down: cost management.
In this article, I’ll share some practical examples as we look at how AI costs can spiral, whether you choose a usage-based model from an established provider like Anthropic or OpenAI, or decide to build, train and host your own model. Of course, there’s a time and place for each option, and we won’t be getting into the specifics of that in this article.
The cloud cost model was complicated. The AI cost model is chaotic.
Over the past 10-15 years, enterprises have become reasonably efficient at managing cloud costs. FinOps emerged as a discipline. Tagging policies were implemented and matured. Teams learned how to use reserved instances and savings plans to reduce costs on public cloud. And finance teams figured out how to read cloud invoices.
But AI costs don’t behave like cloud costs, and the playbook that worked for infrastructure spending won’t work for AI.
Cloud infrastructure pricing, for all its complexity, follows predictable patterns. Compute is billed by the hour. Storage is billed by the gigabyte. Network egress is billed by data volume. With enough discipline, you can forecast it.
AI pricing is fundamentally different. Let’s walk through how this plays out in practice, showing how AI costs can quickly run away from you, leaving you with a much larger bill than your budget allowed for.
First, a quick primer…
Token-based pricing: The hidden multiplier
If you’re consuming AI through LLMs like OpenAI, Anthropic, or Google, you’re paying for tokens. Tokens are calculated for input (when a user enters a prompt or asks a question) and output (when the LLM returns an answer or asks further questions to clarify).
A single chatbot deployed to customer service might process millions of tokens per day, depending on conversation length, user behavior, and prompt design. Small changes in how a model is called can double or halve the bill, and if your AI chatbot is as successful as you’re hoping, you may blow past your estimates entirely.
The screenshot below shows how text entered into an LLM is tokenized, and how the length of the prompt impacts the number of tokens being used. Here, the prompt is tokenized into 27 tokens.
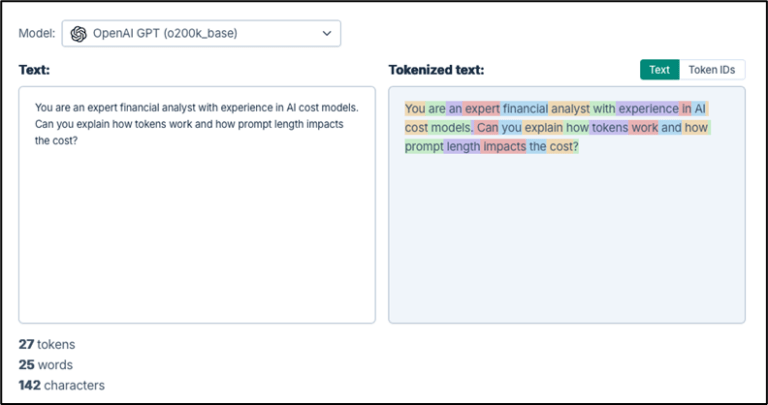
The output received from the model is also tokenized.
Model choice as a cost lever
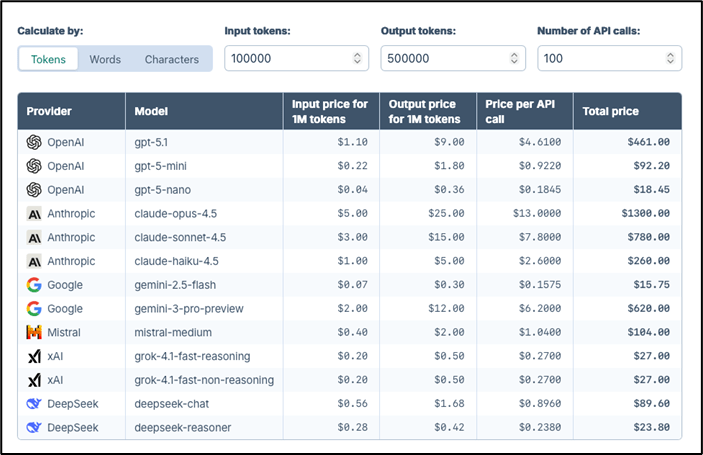
Then there’s the question of which model to use. Using a cost calculator with an estimate of 100,000 tokens as input, 500,000 as output, and 100 API calls allows us to see how costs vary based on the model used.
In the screenshot below, you can see that the cost can vary widely, depending on the model used. For example, using Claude Haiku will cost you $260, but Claude Opus (a model for complex reasoning and analysis) would cost $1,300. Same conversation, fives times the cost.
Cost models for AI are still evolving. AI providers are constantly trying to keep pace with their own costs and the price they charge can change very quickly. This requires close monitoring and adaptability in order to keep track of your estimated deployment and usage costs.
Many organizations today are consuming LLMs across multiple business units without any centralized visibility. This means that Finance only discovers the costs after the fact.
Rolling your own? Beware the GPU cost spiral
If you’re considering building your own model instead of using a third-party LLM, you may find that your costs become even less predictable, depending on whether you are training or using it.
- Training is teaching the AI. You show a model millions of examples, adjusting its internal parameters until it gets good at a task. Training runs can spin up hundreds of GPUs for hours or days, then go dormant. And training isn’t a one-time event: models drift, data changes, regulations evolve. Each retraining cycle consumes significant compute in irregular bursts that don’t fit neatly into monthly forecasts.
- Inference is the AI doing its job. Answering questions, making predictions, generating text. Inference workloads spike unpredictably, and cost optimization strategies that work for batch processing don’t apply to real-time AI applications.
To illustrate my point, let’s take a fictional example of a financial services company that is building a client service chatbot (or virtual service agent). Let’s imagine they’re building and training their own model in AWS vs on-prem (to keep things simple). They don’t have the skills and expertise to do this, so they are about to learn how quickly and unexpectedly costs can spiral.
Training costs
They are planning to spend 48 hours training the model, leveraging 2 x AWS instances p4d.24xlarge (8x A100 GPUs each). This will cost $3,200 (at ~$32.77/hour) on demand. They won’t use reserved instances or savings plans to reduce the cost, as this compute is only needed for this single run. Instead, they opt for on-demand prices. This doesn’t seem too bad, but then of course some unexpected scenarios arise:
| Unexpected scenario | Additional cost |
| Data pre-processing (cleansing, PII redaction) requires 2 weeks on 4× g5.12xlarge instances | +$4,300 |
| Initial results show hallucinations on financial products; training time doubles to 96 hours | +$6,400 |
| Model drifts as customer questions evolve; quarterly retraining required | +$25,600/year |
| Legal flags bias and compliance issues; full pipeline restart needed | +$8,500 |
Now they’re spending $48,000 in the first year, 15 times more than expected.
Inference costs
The team decides to self-host their model on company-controlled infrastructure due to data sovereignty concerns. For inference, they leverage 2x g5.48xlarge instances (2x A100 GPUs) at $2,482/month each, equaling ~ $5,000 a month (including storage and network bandwidth). This cost seems okay, and the model is made available to employees and then customers. But of course, some unexpected scenarios arise:
| Unexpected scenario | Additional cost |
| IT requires redundancy in case the servers fail, and a second environment is needed for disaster recovery | +$5,000/month |
| Marketing drives adoption and conversations grow from 30K to 150K/month | +$10,000/month (4 more instances) |
| 24/7 operations require a staging environment | +$9,900/month |
| Customers love it too, and conversations get longer and more complex | +$9,900/month (more GPUs) |
| MLOps, DevOps, and observability expertise are needed to run the platform | +$66,000/month |
Now the monthly inference cost is 20 times higher than estimated, and the total spend for the first year alone (for both training and inference) is almost $1.3M.
Key takeaways:
This is a highly simplified example, but it shows that:
- Success is expensive. Adoption directly drives cost.
- Training is not usually a one-time event.
- Self-hosting vs using 3rd party LLMs can drive complexity, which drives management costs that can escalate quickly if you haven’t planned effectively for this.
Why traditional cloud cost management falls short
Cloud cost management practices assume a few things that don’t hold true for AI:
| Cloud assumption | AI reality |
|---|---|
| Costs correlate to provisioned resources such as infrastructure | Costs correlate to usage patterns that change constantly |
| Tagging and allocation of resources is fairly mature | AI projects are experimental; ownership shifts frequently |
| Optimization can be done by right-sizing and using reserved instances or savings plans in cloud | Optimization may require prompt engineering, selecting the right model for your use case, and the underlying architecture of your platform |
| Finance can read the bill | AI bills may be complex enough to require engineering expertise to interpret |
The result is that organizations are flying blind. They’re approving AI projects without credible cost models or a full understanding of how costs can increase over time. As a result, Finance teams are discovering overruns months later and companies are struggling to attribute spend to business outcomes.
Five disciplines for managing AI costs
The good news is that this is a solvable problem. But it requires treating AI cost management as an operational discipline, not an afterthought.
Like cloud cost management, certain principles apply when understanding and managing the cost of your AI initiatives.
- Seek visibility before optimization: You can’t manage what you can’t see. Organizations need unified dashboards that track AI spend across cloud, third-party APIs like LLMs, and on-premises or hosted GPU infrastructure (including storage, network, and other related costs).
- Handle cost modeling at the use-case level: AI costs should be modeled per use case, not per resource. For example, what does it cost to run the customer service chatbot? This requires instrumenting consumption visibility and allocation at a granular level.
- Use prompt and model optimization as cost levers: In traditional IT, optimization means right-sizing VMs. In AI, optimization means choosing the right model for the task, engineering efficient prompts, and caching responses where appropriate.
- Ensure your governance spans hybrid environments: Some models in regulated situations need to run on-prem or in private cloud environments. Cost governance must span the full hybrid estate, not just the hyperscaler bill.
- Use Showback or Chargeback models: Business units adopting AI need to understand the cost of what they’re consuming and be accountable for costs. This can be complex, as you need to decide how to allocate shared model training or inference costs across multiple teams.
We can help
Ensono has been helping enterprises navigate cost complexity since the beginning of the Cloud era, when Cloud cost management was still an emerging discipline and bills were arriving faster than organizations could understand them.
AI is following the same pattern, but this time the stakes are higher and the clock is ticking faster.
We approach AI cost management as an Operational discipline, not a Finance responsibility. That means unified visibility across hybrid environments and cost modeling tied to business outcomes.
The bottom line
Cloud FinOps matured because Cloud became too expensive to manage by instinct. AI FinOps will mature for the same reason, but the learning curve is much steeper, and the timeline is much shorter. If your AI cost model today is “we’ll figure it out later”, here’s the uncomfortable truth: Later will arrive sooner than you think.
Get ahead of AI costs before they get ahead of you.
Social Share
Don't miss the latest from Ensono
Keep up with Ensono
Innovation never stops, and we support you at every stage. From infrastructure-as-a-service advances to upcoming webinars, explore our news here.
Blog Post | 24 June 2026 | Technology trends
Why Mainframe Exit Projects Fail in the Age of GenAI: An Ensono Q&A
Blog Post | 18 June 2026 | Industry trends
How Private Equity Ownership Is Changing the Modernization Conversation
Blog Post | 17 June 2026 | Industry trends